










Obfuscation is the practice of concealing or making information difficult to locate. This is accomplished in application security by adding complexity to the execution flow, adding procedures to otherwise simple computations, or even inserting completely worthless code. These strategies can be used to conceal important application data, crucial code, or user data within a piece of software.
Protecting data in apps via obfuscation
Attackers are distracted and confused by obfuscation, making it considerably more difficult for them to find data contained in your applications or exploit vulnerabilities. According to Veracode’s State of Software Security Report, 76% of software applications have at least one security fault, with 66% having an OWASP Top 10 vulnerability. In our recent investigation, we discovered major security flaws in 77% of mobile finance apps.
Obfuscating code can be done in a number of ways, and the most effective protection schemes combine several of them. The value of the application code and data it contains will decide the level of sophistication and extent of code obfuscation you should utilize.
Obfuscation of flow control
The goal of control flow obfuscation is to make the execution flow more complicated. Both manual and automated reverse engineering are slowed as a result of this. This is accomplished by generating new execution pathways and dividing old paths into many segments. For example, you can inline functions (replace method calls with the actual method body) and calculated jumps can be used to replace calls to subroutines.
Control flow flattening is one of the most effective techniques of control flow obfuscation. An ordinary function or collection of functions in an application is transformed into a state machine using this obfuscation approach. Creating a dispatcher to control the execution of each piece after first breaking the function into several smaller sections. The function behavior may appear strange or even illogical due to this complex form.
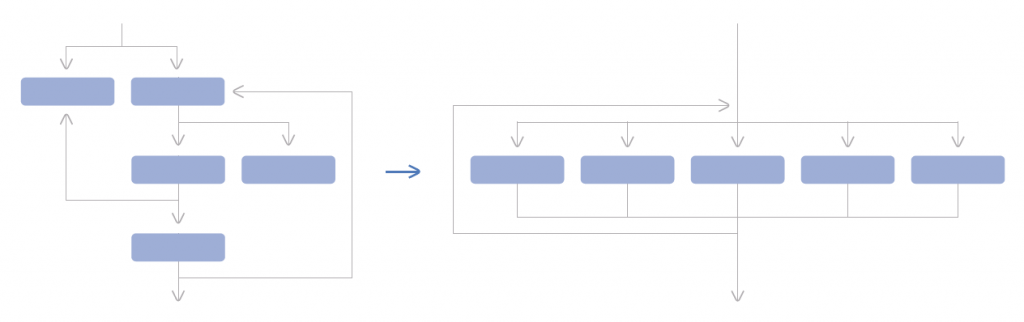
Conceptual illustration of flattening the control flow
Bad actors will have a tougher time finding where sensitive data is processed or maintained if the critical code pathways that operate on it are obscured.
Code that isn’t useful
Junk code is code that is added to a program but is never executed. The addition of this unneeded code increases the number of potential targets that attackers must assess, slowing down the pace of their attack. This form of defense can use anything from entire functions to single instructions.
Junk code can have any shape you like because it never runs. To make the analysis even more difficult, you can make modified copies of valid code. Garbage instructions can be created in such a way that typical reverse engineering tools have problems interpreting them in more complex scenarios. Automatic analysis is severely hampered when legitimate code is tangled in.
This form of security can considerably increase data security. Guaranteed-to-never-execute instructions can appear to do any number of valid data modifications. Automated tools will be fooled into believing that data is being referenced, used, and modified in a variety of ways when none of this is the case. During manual analysis, an attacker may become convinced that data that you don’t care about has been subjected to some algorithm or decoding.
Code of deception
Decoy code is similar to garbage code in that it is injected into an application and run but does nothing. The fundamental goal of decoy code is to conceal the actual code’s intended purpose or result. For instance, computing a value that is never utilized or running a complete block of code and then discarding the output.
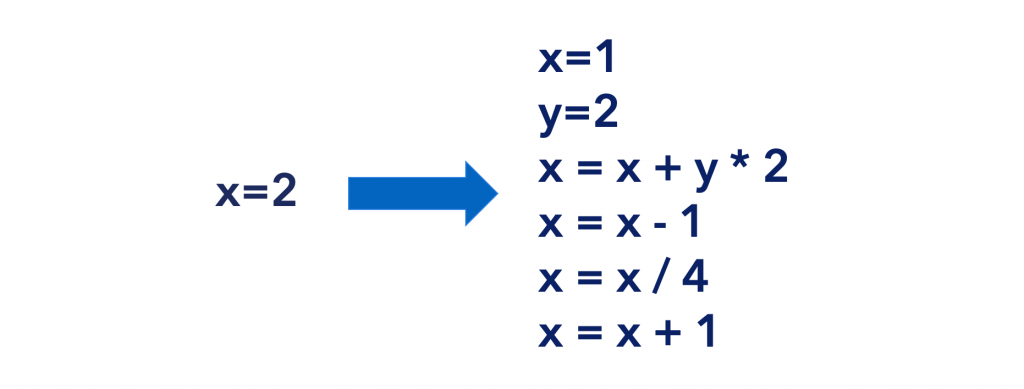
An example of how decoy code can be used to obscure operations.
Zero sum operations, such as the ones stated, are a good way to hide the meaning or value of valid code. For example, among a sea of meaningless computations, a beautiful and straightforward proprietary data processing algorithm can be hidden.
Obfuscation of string literals
Strings in an application are valuable to an attacker because they are easily found and can provide valuable information about the code they want to target. They frequently contain messages and data that users view while using the app, making it easy for malicious actors to map features to code.
String literal obfuscation protects strings by converting them into unrecognizable characters. The purpose is to keep data hidden from automated scanning and manual scrutiny at all times, whether through encoding or encryption. This includes both on disk and during the application’s execution.
There are a few common methods for accomplishing this. The first step is to encrypt every string in the program and then decrypt it once it’s launched. Alternatively, strings can be left in an obfuscated state and decoded or decrypted as needed. Because the data must be used at some point, you must keep the length of time it spends in the open to a minimum.
Using advanced obfuscation techniques
You can use a variety of free obfuscators to apply simple obfuscation to your code. These, on the other hand, offer only a sliver of protection. More complex code obfuscation approaches should be used by developers of mission-critical apps that handle sensitive personal information, financial information, or patient data.
whiteCryption Code Protection employs the techniques mentioned above, as well as others, to offer multilayer obfuscation that prevents reverse engineering and protects application data. Code obfuscation is one of the in-app defensive technologies used by Code Protection to help businesses safeguard their software and consumers’ investments.




{kind=link}